# pacotes do R
library(reticulate)
library(knitr)
library(kableExtra)
library(plotly)
library(factoextra)
library(tidyverse)Neste post, faço uma atualização de Como votaram os senadores em 2019, utilizando os dados das votações de 2023 e considerando algumas alterações no código. Em relação ao código, agora incluo alguns gráficos em Python com o plotnine. Essa biblioteca segue o mesmo padrão do ggplot2 implementado no R.
Carregando os pacotes/bibliotecas
Primeiro, apresento os pacotes, em R e Python, que serão utilizados nessa análise.
# bibliotecas do python
import requests, pandas as pd, numpy as np
from plotnine import *
theme_set(theme_bw());Leitura dos dados
A seguir, é feita a leitura dos dados das sessões e das votações com o Python. Veja a estrutura dos dados:
# código em python
url = "https://legis.senado.leg.br/dadosabertos/arquivos/ListaVotacoes2023.json"
response = requests.get(url, headers = {"Accept": "application/json"}).json()
# response["ListaVotacoes"]["Votacoes"]Além desses dados, é possível explorar outras informações no site dados abertos do Senado Federal.
Pela forma como os dados estão estruturados, criarei dois data frames:
- sessao: contém as informações das sessões, como o ano da matéria, código da matéria, código da sessão etc;
- votos: contém as informações dos votos dos parlamentares, como o código do parlamentar, nome do parlamentar, sigla do partido, voto, link para a foto oficial do parlamentar etc.
Dados de Sessões
# código em python
sessao = pd.DataFrame(response["ListaVotacoes"]["Votacoes"]["Votacao"])
sessao.head()| CodigoSessao | SiglaCasa | CodigoSessaoLegislativa | TipoSessao | NumeroSessao | DataSessao | HoraInicio | CodigoVotacaoSve | CodigoSessaoVotacao | SequencialSessao | Secreta | Resultado | TotalVotosSim | TotalVotosNao | TotalVotosAbstencao | CodigoMateria | SiglaMateria | NumeroMateria | AnoMateria | SiglaCasaMateria | DescricaoObjetivoProcesso | DescricaoIdentificacaoMateria | SiglaComissaoRequerimento |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 320695 | SF | 868 | DOR | 1 | 2023-02-08 | 16:00 | 3995 | 6674 | 1 | S | A | 72 | 2 | 1 | 155773 | PDL | 00002 | 2023 | SF | Revisora | PDL 2/2023 | NaN |
| 325622 | SF | 868 | DOR | 21 | 2023-03-28 | 14:00 | 3996 | 6675 | 1 | N | A | NaN | NaN | NaN | 138100 | PLP | 00189 | 2019 | SF | Iniciadora | PLP 189/2019 | NaN |
| 329137 | SF | 868 | DOR | 33 | 2023-04-19 | 14:00 | 3997 | 6676 | 1 | N | A | NaN | NaN | NaN | 156944 | PRS | 00046 | 2023 | SF | NaN | PRS 46/2023 | NaN |
| 333154 | SF | 868 | DOR | 43 | 2023-05-09 | 14:00 | 3999 | 6677 | 1 | N | A | NaN | NaN | NaN | 156611 | PL | 01825 | 2022 | SF | Substitutivo | PL 1825/2022 (Substitutivo-CD) | NaN |
| 333154 | SF | 868 | DOR | 43 | 2023-05-09 | 14:00 | 4000 | 6678 | 2 | N | A | NaN | NaN | NaN | 133899 | PLS | 00332 | 2018 | SF | Iniciadora | PLS 332/2018 | NaN |
| 333770 | SF | 868 | DOR | 44 | 2023-05-10 | 14:00 | 4001 | 6679 | 1 | N | A | NaN | NaN | NaN | 139697 | PLP | 00245 | 2019 | SF | Iniciadora | PLP 245/2019 | NaN |
Para facilitar a visualização, excluí as colunas Votos e DescricaoVotacao.
Dados dos votos
O data frame contendo as informações dos votos será extraído da seguinte forma:
# código em python
votos = pd.concat(
[
pd.DataFrame(sessao["Votos"][s]["VotoParlamentar"]).assign(
CodigoSessao = sessao["CodigoSessao"][s],
CodigoSessaoVotacao = sessao["CodigoSessaoVotacao"][s]
)
for s in sessao.index
],
ignore_index=True
)
votos.head()A seguir, são apresentadas algumas linhas do data frame votos.
| CodigoParlamentar | NomeParlamentar | SexoParlamentar | SiglaPartido | SiglaUF | Url | Foto | Tratamento | Voto | UrlPaginaParticular | DescricaoVoto | CodigoSessao | CodigoSessaoVotacao |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22 | Esperidião Amin | M | PP | SC | http://www25.senado.leg.br/web/senadores/senador/-/perfil/22 | http://www.senado.leg.br/senadores/img/fotos-oficiais/senador22.jpg | Senador | Votou | NaN | NaN | 320695 | 6674 |
| 35 | Jader Barbalho | M | MDB | PA | http://www25.senado.leg.br/web/senadores/senador/-/perfil/35 | http://www.senado.leg.br/senadores/img/fotos-oficiais/senador35.jpg | Senador | AP | http://jaderbarbalho.com.br/ | Atividade parlamentar | 320695 | 6674 |
| 70 | Renan Calheiros | M | MDB | AL | http://www25.senado.leg.br/web/senadores/senador/-/perfil/70 | http://www.senado.leg.br/senadores/img/fotos-oficiais/senador70.jpg | Senador | Votou | https://www.renancalheiros.com.br/ | NaN | 320695 | 6674 |
| 285 | Marcio Bittar | M | UNIÃO | AC | http://www25.senado.leg.br/web/senadores/senador/-/perfil/285 | http://www.senado.leg.br/senadores/img/fotos-oficiais/senador285.jpg | Senador | Votou | NaN | NaN | 320695 | 6674 |
| 345 | Flávio Arns | M | PSB | PR | http://www25.senado.leg.br/web/senadores/senador/-/perfil/345 | http://www.senado.leg.br/senadores/img/fotos-oficiais/senador345.jpg | Senador | Votou | http://www.flavioarns.com.br | NaN | 320695 | 6674 |
| 470 | Chico Rodrigues | M | PSB | RR | http://www25.senado.leg.br/web/senadores/senador/-/perfil/470 | http://www.senado.leg.br/senadores/img/fotos-oficiais/senador470.jpg | Senador | Votou | NaN | NaN | 320695 | 6674 |
Sessão
Incialmente, verificarei quais são as matérias mais antigas votadas nas sessões. É possível observar que são as matérias de 2018 e 2019.
# código em python
sessao.value_counts("AnoMateria").to_frame("n").reset_index() AnoMateria n
0 2023 117
1 2019 11
2 2022 5
3 2021 4
4 2018 3
5 2020 1As proposições são apresentadas por siglas. A seguir, são apresentadas as siglas encontradas nas sessões de 2023.
- MSF: Mensagem ao Senado Federal;
- OFS: Ofício “S”;
- PEC: Proposta de Emenda à Constituição;
- PLP: Projeto de Lei Complementar
- PL: Projeto de Lei
- MPV: Medida Provisória;
- RQS: Requerimento do Senado
- REQ: Requerimento
- PRS: Projeto de Resolução do Senado.
- PLS: Projeto de Lei do Senado;
- PDL: Projeto de Decreto Legislativo
É possível observar que grande parte das sessões é composta de Mensagem ao Senado Federal (MSF), Ofício “S” (OFS), Proposta de Emenda à Constituição (PEC), Projeto de Lei Complementar (PLP) e Projeto de Lei (PL).
# código em python
(sessao.value_counts("SiglaMateria").to_frame("n").reset_index()
.pipe(lambda _: ggplot(_, aes(y = "n", x = "reorder(SiglaMateria, n)")) +
geom_col(alpha = 0.75, fill = "#fc035a") +
labs(x = "", y = "número de sessões",
title = "Sigla da Matéria") +
theme(legend_position = "none") +
coord_flip()))<Figure Size: (640 x 480)>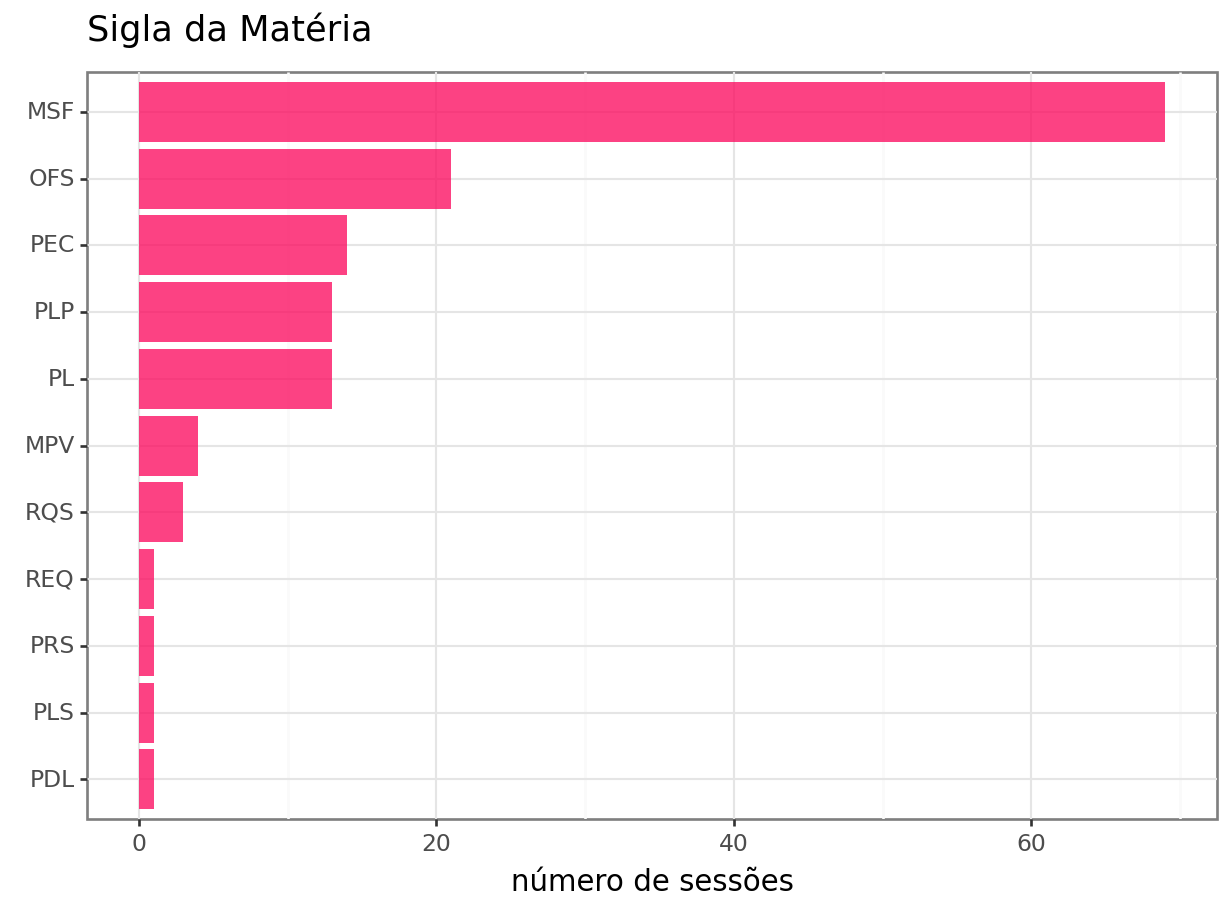
Votos
Incialmente, verificarei quantos senadores cada partido teve no período de 2023.
(votos.loc[:,["SiglaPartido","NomeParlamentar"]]
.drop_duplicates()
.value_counts("SiglaPartido").to_frame("n").reset_index()
.pipe(lambda _: ggplot(_, aes(y = "n", x = "reorder(SiglaPartido, n)")) +
geom_col(alpha = 0.75, fill = "#fc035a") +
labs(x = "", y = "número de senadores", title = "Número de senadores") +
theme(legend_position = "none") +
coord_flip()))<Figure Size: (640 x 480)>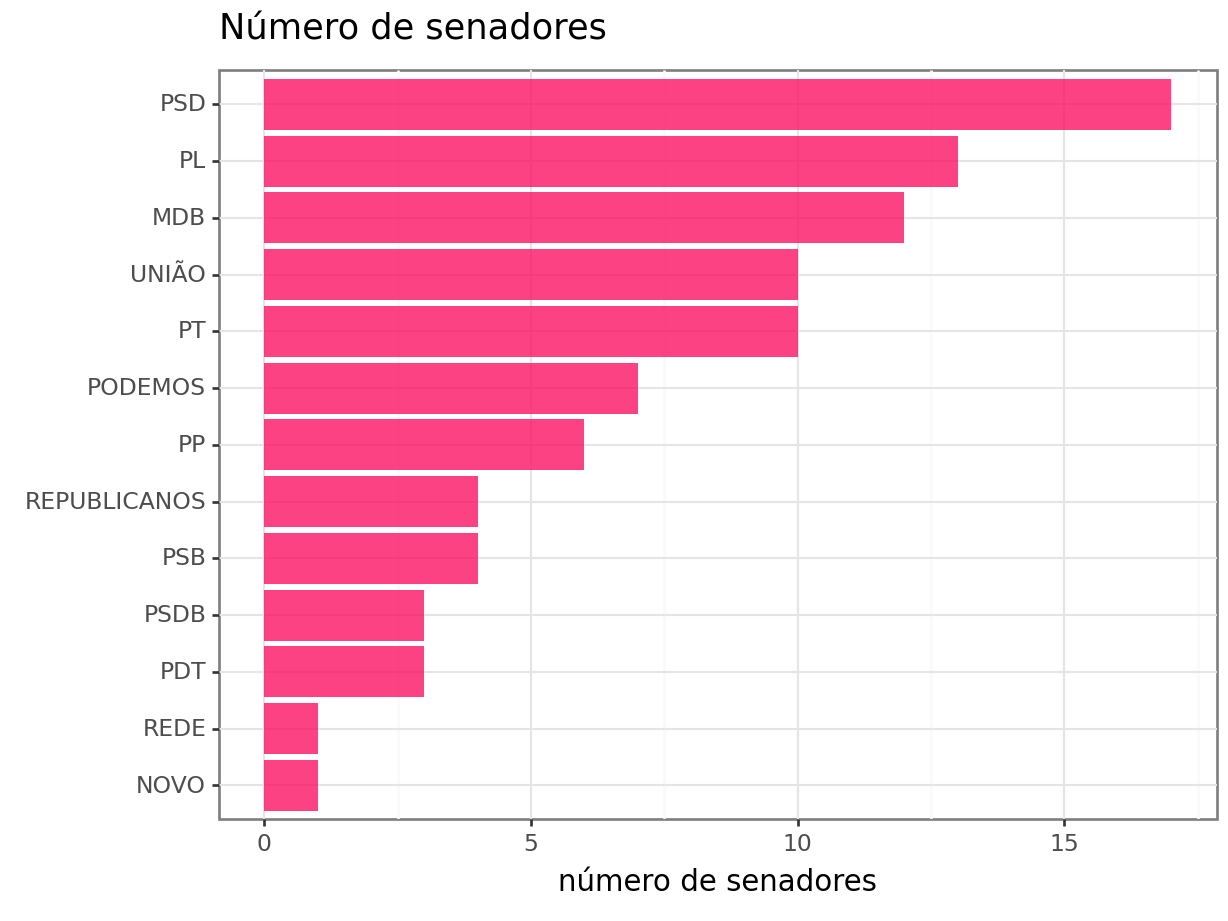
Os partidos PSD, PL e MDB possuem, respectivamente, os maiores números de senadores. Já os partidos NOVO e REDE contam apenas com um senador cada. Esses senadores são, respectivamente, os senadores Eduardo Girão e Randolfe Rodrigues.
# código em python
(votos.query("SiglaPartido in ['REDE', 'NOVO']")
.value_counts(["SiglaPartido", "NomeParlamentar"]).reset_index()) SiglaPartido NomeParlamentar count
0 NOVO Eduardo Girão 141
1 REDE Randolfe Rodrigues 141A seguir, são apresentados os tipos de votos observados em 2023.
# código em python
(votos.Voto.value_counts().to_frame("n").reset_index()
.pipe(lambda _: ggplot(_, aes(y = "n", x = "reorder(Voto, n)")) +
geom_col(alpha = 0.75, fill = "#fc035a") +
labs(x = "", y = "número de sessões", title = "Voto") +
theme(legend_position = "none") +
coord_flip()))<Figure Size: (640 x 480)>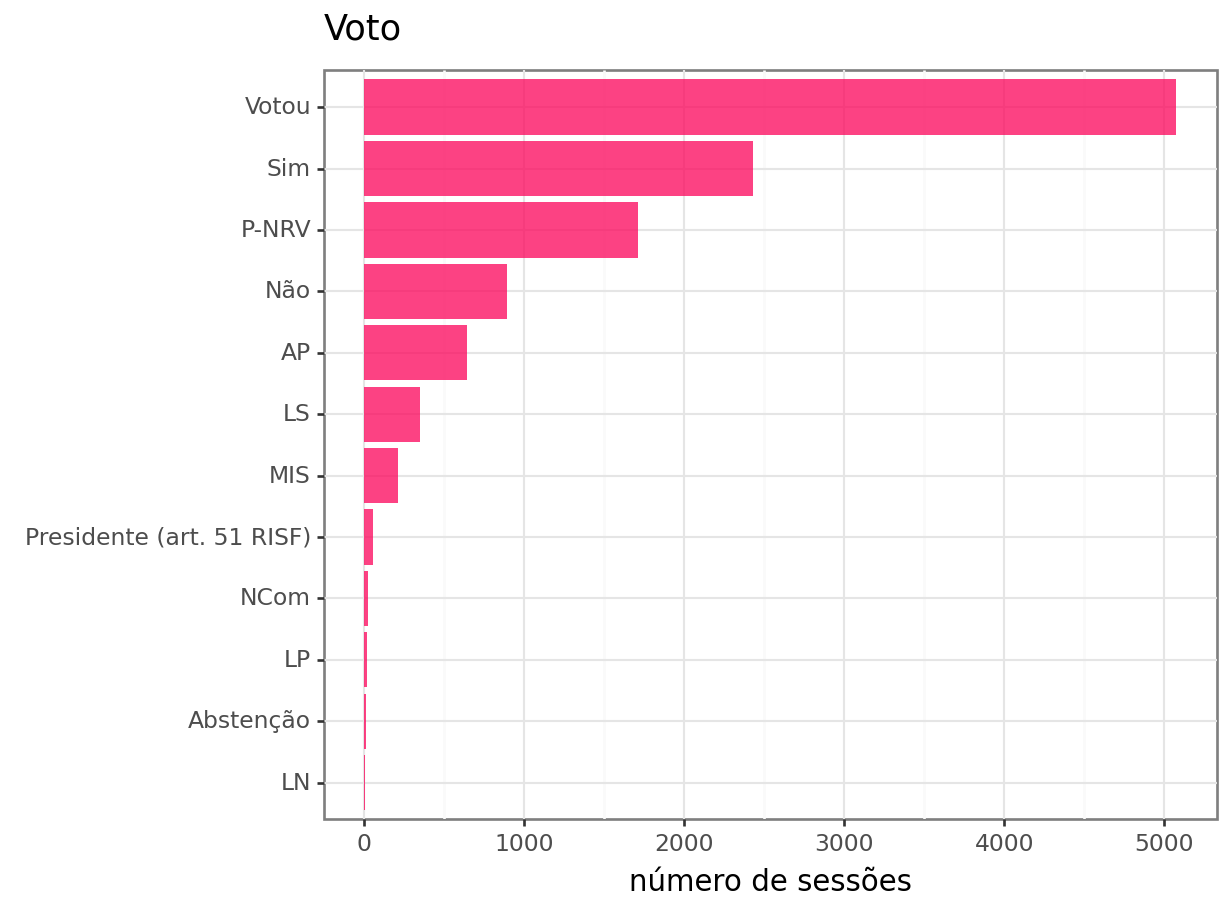
As siglas observadas no gráfico significam:
- Votou: normalmente é indicada quando a votação é secreta
- Sim: votou sim
- P-NRV: presente não registrou voto
- Não: votou não
- AP: atividade parlamentar
- LS: licença saúde
- MIS: presente (em Missão)
- Presidente (Art. 51 RISF): é voto do presidente que o faz
- NCom: não compareceu
- LP: licença particular
- Abstenção:
- LN: licença nojo
É possível verificar que as categorias com maiores frequências são Votou, Sim e P-NRV.
Uma curiosidade: licença nojo é concedida nos casos de falecimento de cônjuge, companheiro, pais, madrasta ou padrasto, filhos, enteados, menor sob guarda ou tutela e irmãos.
Em relação ao número de licenças saúde, conforme fiz no post anterior, apresento o top 10 dos senadores com maior número de licenças.
# código em python
(votos.query("Voto == 'LS'")
.NomeParlamentar.value_counts().to_frame("n").reset_index()
.nlargest(10, "n", keep = "all")
.sort_values(by = ["n","NomeParlamentar"], ascending=[True, False])
.assign(NomeParlamentar = lambda _: pd.Categorical(_.NomeParlamentar, _.NomeParlamentar))
.pipe(lambda _: ggplot(_, aes(y = "n", x = "reorder(NomeParlamentar, n)")) +
geom_col(alpha = 0.75, fill = "#fc035a") +
labs(x = "", y = "número de licenças saúde",
title = "Licenças saúde") +
theme(legend_position = "none") +
coord_flip()))<Figure Size: (640 x 480)>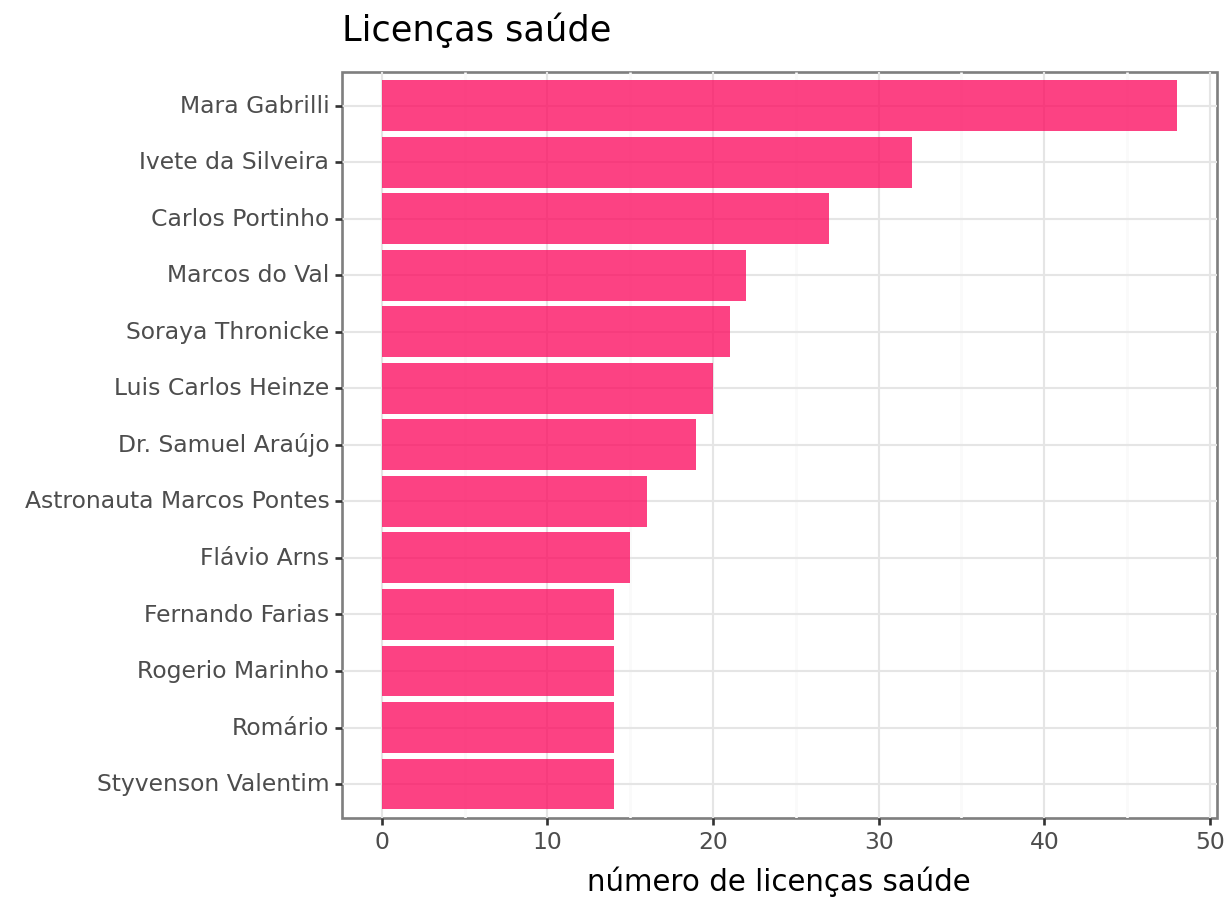
Os senadores com maior número de lincenças saúde são Mara Gabrilli, Ivete da Silveira, Carlos Portinho e Marcos do Val.
Além disso, seria interessante verificar quais senadores apresentaram a maior frequência de voto P-NRV (presente – não registrou voto). A senadora Eliziane Gama apresentou a maior frequência de votos nessa categoria, seguida por Renan Calheiros e Magno Malta.
# código em python
(votos.query("Voto == 'P-NRV'")
.NomeParlamentar.value_counts().to_frame("n").reset_index()
.nlargest(10, "n", keep = "all")
.sort_values(by = ["n","NomeParlamentar"], ascending=[True, False])
.assign(NomeParlamentar = lambda _: pd.Categorical(_.NomeParlamentar, _.NomeParlamentar))
.pipe(lambda _: ggplot(_, aes(y = "n", x = "NomeParlamentar")) +
geom_col(alpha = 0.75, fill = "#fc035a") +
labs(x = "", y = "número de presenças sem registrar voto",
title = "Presenças sem registrar voto") +
theme(legend_position = "none") +
coord_flip()))<Figure Size: (640 x 480)>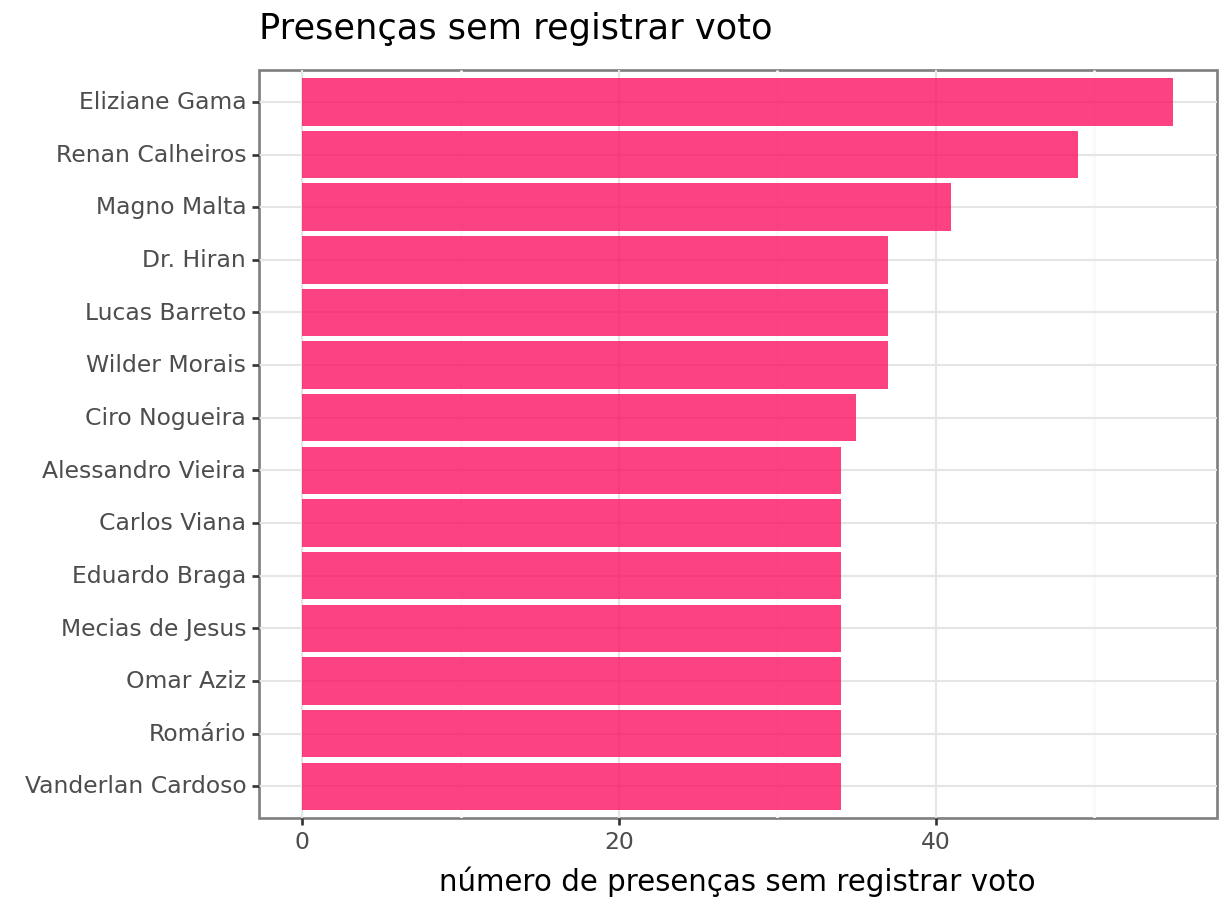
Comportamento dos senadores
Para verificar quais senadores apresentaram comportamentos similares em relação aos votos nesse período, para as análises a seguir, considerarei apenas os votos Sim e Não.
# código em python
votos_validos = votos.query("Voto == 'Sim' | Voto == 'Não'")
mudancas_partidos = (votos_validos.value_counts(["NomeParlamentar", "SiglaPartido"])
.to_frame("n").reset_index()
.value_counts("NomeParlamentar").to_frame("n").reset_index()
.query("n > 1"))Primeiro, verificarei quais senadores mudaram de partido nesse período. É possível observar que Zequinha Marinho, Soraya Thronicke, Rodrigo Cunha e Alessandro Vieira mudaram de partido em 2023.
mudancas_partidos NomeParlamentar n
0 Zequinha Marinho 2
1 Soraya Thronicke 2
2 Rodrigo Cunha 2
3 Alessandro Vieira 2Como o senador pode mudar de comportamento de acordo com o partido, irei diferenciar esses períodos. Para isso, nos casos de mudança de partido, adicionarei o nome do partido após o nome do senador.
# código em python
votos_validos = votos_validos.assign(NomeParlamentar = np.where(votos_validos["NomeParlamentar"].isin(mudancas_partidos["NomeParlamentar"]),
votos_validos['NomeParlamentar'] + ' - ' + votos_validos['SiglaPartido'],
votos_validos['NomeParlamentar']))No gráfico abaixo, apresento as menores frequências de votos (sim ou não).
# código em python
(votos_validos.NomeParlamentar.value_counts(ascending = False).to_frame("n").reset_index()
.nsmallest(10, "n", keep = "all")
.assign(NomeParlamentar = lambda _: pd.Categorical(_.NomeParlamentar, _.NomeParlamentar))
.pipe(lambda _: ggplot(_, aes(y = "n", x = "reorder(NomeParlamentar, -n)")) +
geom_col(alpha = 0.75, fill = "#fc035a") +
labs(x = "", y = "número de votos (sim ou não)",
title = "Número de votos (sim ou não)") +
theme(legend_position = "none") +
coord_flip()))<Figure Size: (640 x 480)>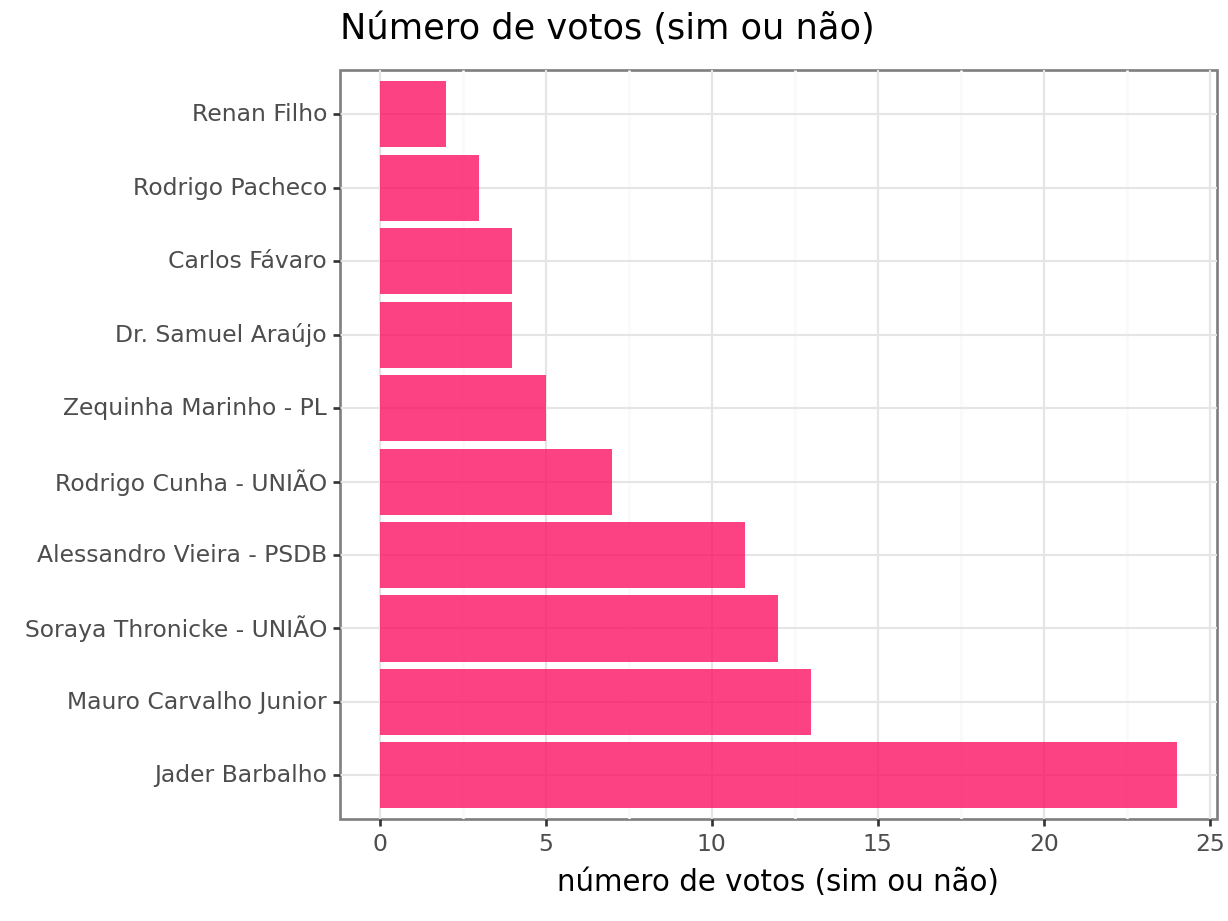
É possível observar que os senadores Renan Filho, Rodrigo Pacheco, Carlos Fávero, Dr. Samuel Araújo e Zequinha Marinho - PL apresentaram até 5 votos (sim ou não) nesse período. Para não considerar dados de senadores com número reduzido de votações, considerarei apenas senadores com mais de 10 votos.
# código em python
senadores_mais_10_votos = (votos_validos.NomeParlamentar.value_counts().to_frame("n").reset_index()
.query("n > 10")
.filter(["NomeParlamentar"]))
votos_validos = votos_validos[votos_validos["NomeParlamentar"].isin(senadores_mais_10_votos["NomeParlamentar"])]Agora, com os dados filtrados e processados, farei o cálculo da matriz de dissimilaridades. Essa matriz indicará quais senadores apresentaram comportamentos similares em termos de votos (sim e não) no ano de 2023.
A medida de dissimilaridade entre dois senadores A e B é dada por:
\[d_{A,B} = 1 - \frac{|A \cap B|}{|A \cup B|},\]
em que \(|A \cap B|\) indica o número de votações que os senadores A e B votaram da mesma forma e \(|A \cup B|\) indica o número de votações que os senadores A e B participaram. Assim, senadores que votam da mesma forma em todas as sessões apresentam dissimilaridade igual a 0. Já senadores que sempre votam de forma diferente, apresentam dissimilaridade igual a 1.
Uma questão técnica para esses dados é que nem todos os senadores votaram em todas as sessões. Dessa forma, a dissimilaridade será calculada entre os senadores com base apenas nas sessões nas quais os dois senadores em questão votaram. Além disso, não é possível calcular a dissimilaridade entre dois senadores enquanto estavam em partidos distintos. Por isso, desconsiderarei os senadores nessa situação.
O código abaixo executa o processamento necessário e calcula a matriz de dissimilaridades entre os senadores.
# código em R
dados_wider <- py$votos_validos %>%
filter(!(
NomeParlamentar %in% c(
"Alessandro Vieira - PSDB",
"Rodrigo Cunha - UNIÃO",
"Soraya Thronicke - UNIÃO",
"Zequinha Marinho - PL",
"Mauro Carvalho Junior"
)
)) %>%
select(Voto, CodigoSessao, CodigoSessaoVotacao, NomeParlamentar) %>%
mutate(Voto = case_when(Voto == "Sim" ~ 1, TRUE ~ 0)) %>%
pivot_wider(names_from = "NomeParlamentar", values_from = "Voto")
nomes <- sort(colnames(dados_wider)[-(1:2)])
dissim <- matrix(0, nrow = length(nomes), ncol = length(nomes))
dimnames(dissim) <- list(nomes, nomes)
for (i in 1:(nrow(dissim) - 1)) {
for (j in (i + 1):ncol(dissim)) {
aux <- cbind(dados_wider[, colnames(dados_wider) == rownames(dissim)[i]], dados_wider[, colnames(dados_wider) == rownames(dissim)[j]]) %>%
na.omit()
dissim[i, j] <- 1 - sum(aux[, 1] * aux[, 2]) / (sum(aux[, 1]) + sum(aux[, 2]) - sum(aux[, 1] * aux[, 2]))
dissim[j, i] <- dissim[i, j]
if (is.na(dissim[j, i]))
print(paste0("i:", i, " j: ", j))
}
}Uma vez que tenho a matriz de dissimilaridades calculadas, posso utilizar o método de escalonamento multidimensional. Assim, é possível obter uma visualização das dissimilaridades em um gráfico de duas dimensões (para mais detalhes, ver Data Science, Marketing & Business e Introdução à Análise Exploratória de Dados Multivariados do professor Pedro J. Fernandez). Para isso, utilizarei a função cmdscale.
# código em R
mds <- cmdscale(na.omit(dissim))
resultados <- tibble(senador = rownames(mds),
coord1 = mds[, 1],
coord2 = mds[, 2])
head(resultados)# A tibble: 6 × 3
senador coord1 coord2
<chr> <dbl> <dbl>
1 Alan Rick 0.101 0.0510
2 Alessandro Vieira - MDB -0.121 0.135
3 Ana Paula Lobato -0.274 -0.0410
4 Angelo Coronel -0.189 -0.0156
5 Astronauta Marcos Pontes 0.260 -0.0980
6 Augusta Brito -0.281 -0.0799Como os dados foram projetados em duas dimensões, posso utilizar um gráfico de dispersão para entender as relações entre os senadores. É importante ressaltar que pontos mais próximos indicam comportamentos similares em relação às votações. Você pode dar dois cliques no nome do partido na legenda para visualizar apenas os senadores do partido em questão ou um apenas um clique para remover o partido em questão da visualização.
É interessante notar como os senadores do UNIÃO e PODEMOS apresentam grande variabilidade, ou seja, não votam uniformemente em bloco. Em contrapartida, os senadores do PT apresentam uma grande coesão.
# código em R
resultados <- resultados %>%
left_join(
py$votos_validos %>%
select(NomeParlamentar, SiglaPartido) %>%
distinct(),
by = c("senador" = "NomeParlamentar")
)
fig1 <- resultados %>%
ggplot(aes(
coord1,
coord2,
color = SiglaPartido,
text = paste("Senador: ", senador, '<br>Partido:', SiglaPartido)
)) +
geom_hline(yintercept = 0, color = "grey") +
geom_vline(xintercept = 0, color = "grey") +
geom_point() +
labs(x = NULL, y = NULL, color = NULL) +
theme_void()
ggplotly(fig1, tooltip = "text") Os senadores podem ser agrupados de acordo com os posicionamentos do gráfico anterior. Lembrando que observações mais próximas indicam que os senadores apresentam comportamento similar nas votações. A seguir apresento um dendrograma de agrupamento dos senadores. Destaco a figura em 6 grupos, mas a leitura pode ser feita de forma geral.
# código em R
cluster <- hclust(as.dist(dissim))
fviz_dend(
cluster,
cex = 0.85,
k = 6,
main = "Agrupamento dos Senadores",
color_labels_by_k = TRUE,
horiz = TRUE,
labels_track_height = 0.35
) +
theme_void()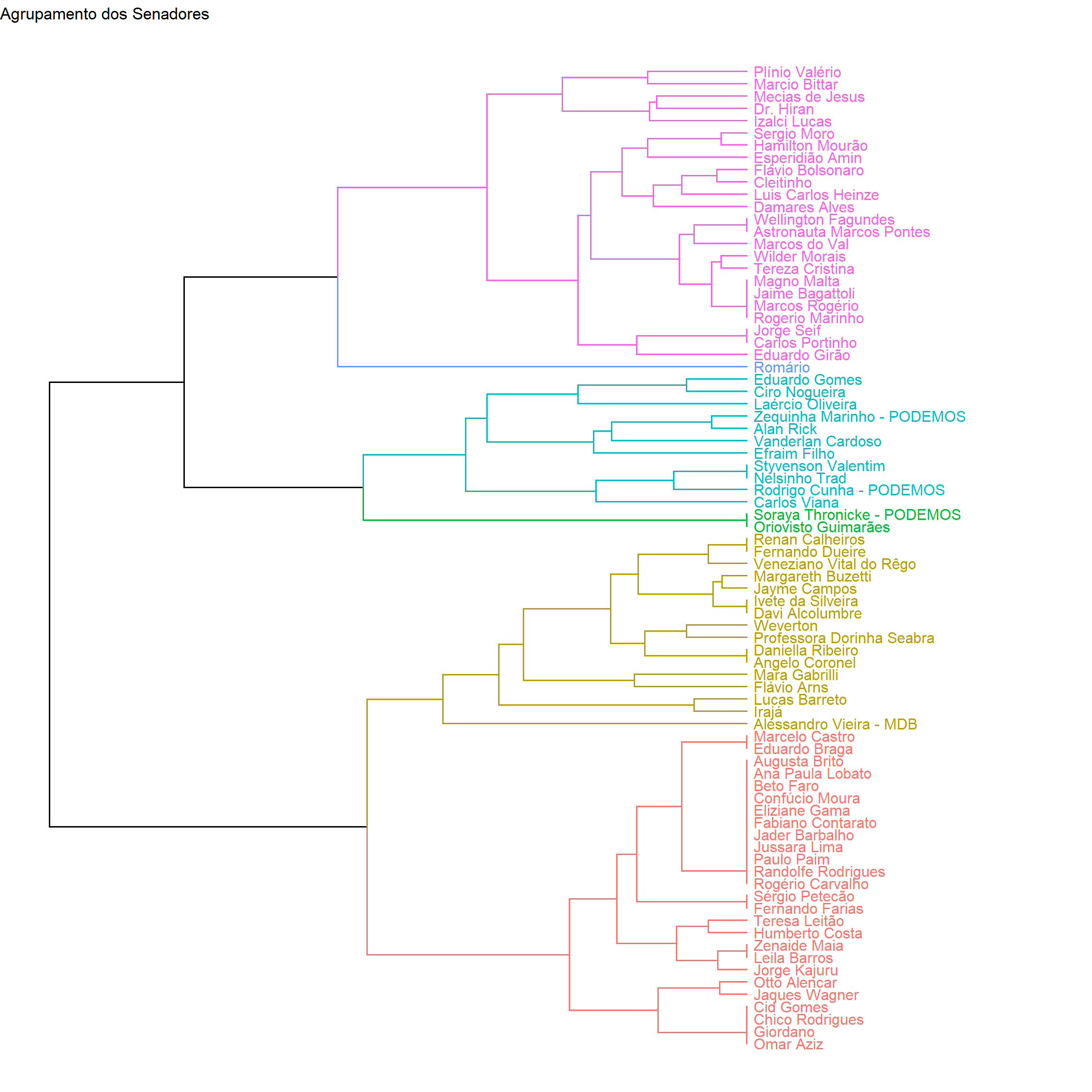
Note como Romário e Alessandro Vieira (enquanto no MDB) apresentaram um comportamento diferenciado em relação aos demais blocos, ou seja, não apresentaram um comportamento similar a nenhum senador.
Uma forma alternativa de se mostrar os resultados apresentados no último gráfico se dá a partir do seguinte dendrograma filogenético.
library(igraph)
fviz_dend(
cluster,
k = 6,
cex = 0.85,
color_labels_by_k = TRUE,
type = "phylogenic",
repel = TRUE,
phylo_layout = "layout.gem"
) +
theme_void()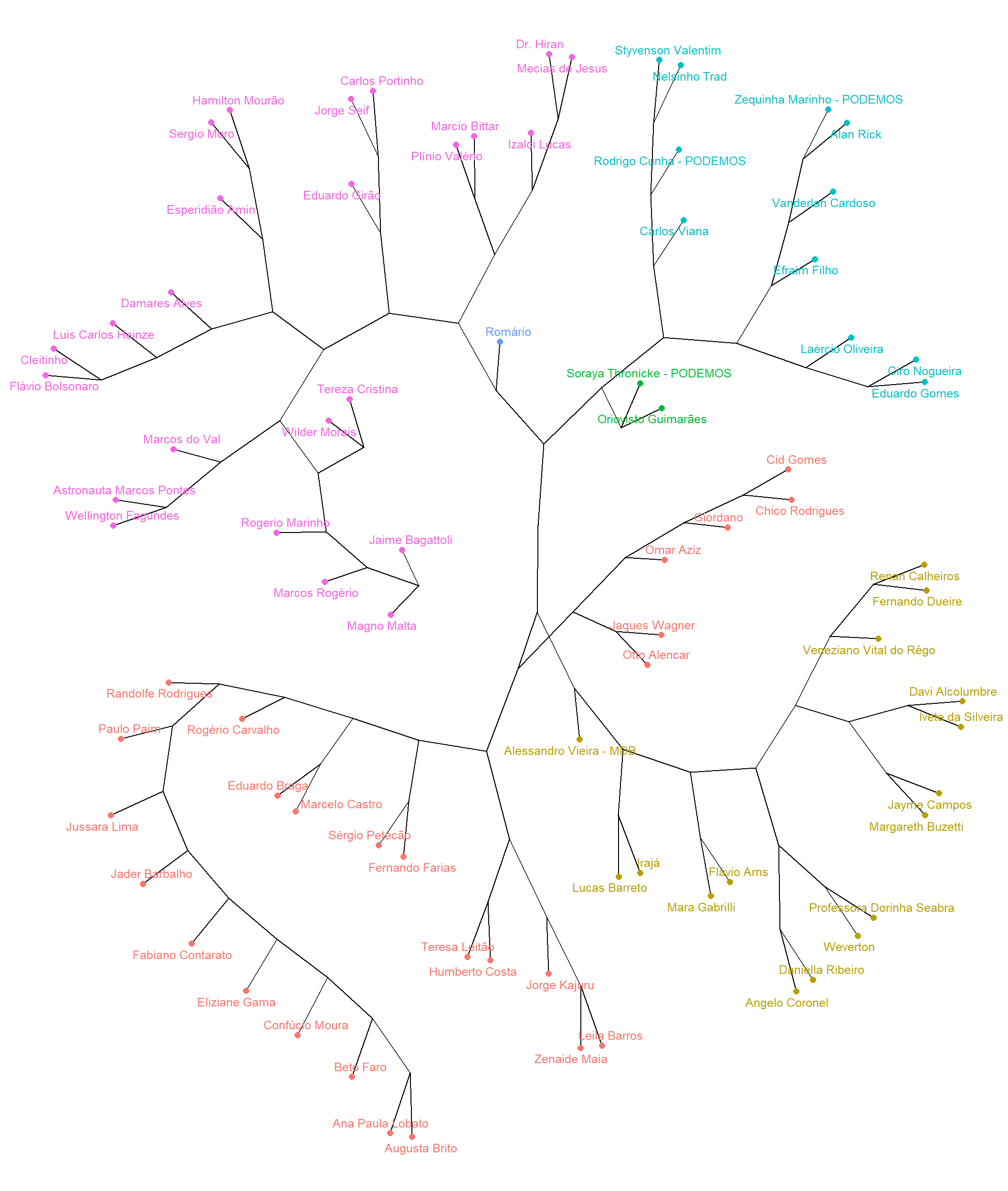
Comportamento dos partidos
Ao visualizar as similaridades dos senadores em um gráfico bidimensional é imediata a sugestão de uma medida de coesão dos partidos. Para isso, considerarei a média da distância de cada senador para o centroide (centro de massa dos votos dos senadores) do respectivo partido.
# código em R
resultados %>%
nest(data = -SiglaPartido) %>%
mutate(variabilidade = map_dbl(data, ~ mean((.x$coord1 - mean(.x$coord1)) ^
2 + (.x$coord2 - mean(.x$coord2)) ^ 2
))) %>%
filter(!(SiglaPartido %in% c("REDE", "NOVO"))) %>%
ggplot(aes(reorder(SiglaPartido, variabilidade), variabilidade)) +
geom_col(fill = "#fc035a") +
labs(x = NULL, y = "variabilidade") +
coord_flip() +
theme_bw()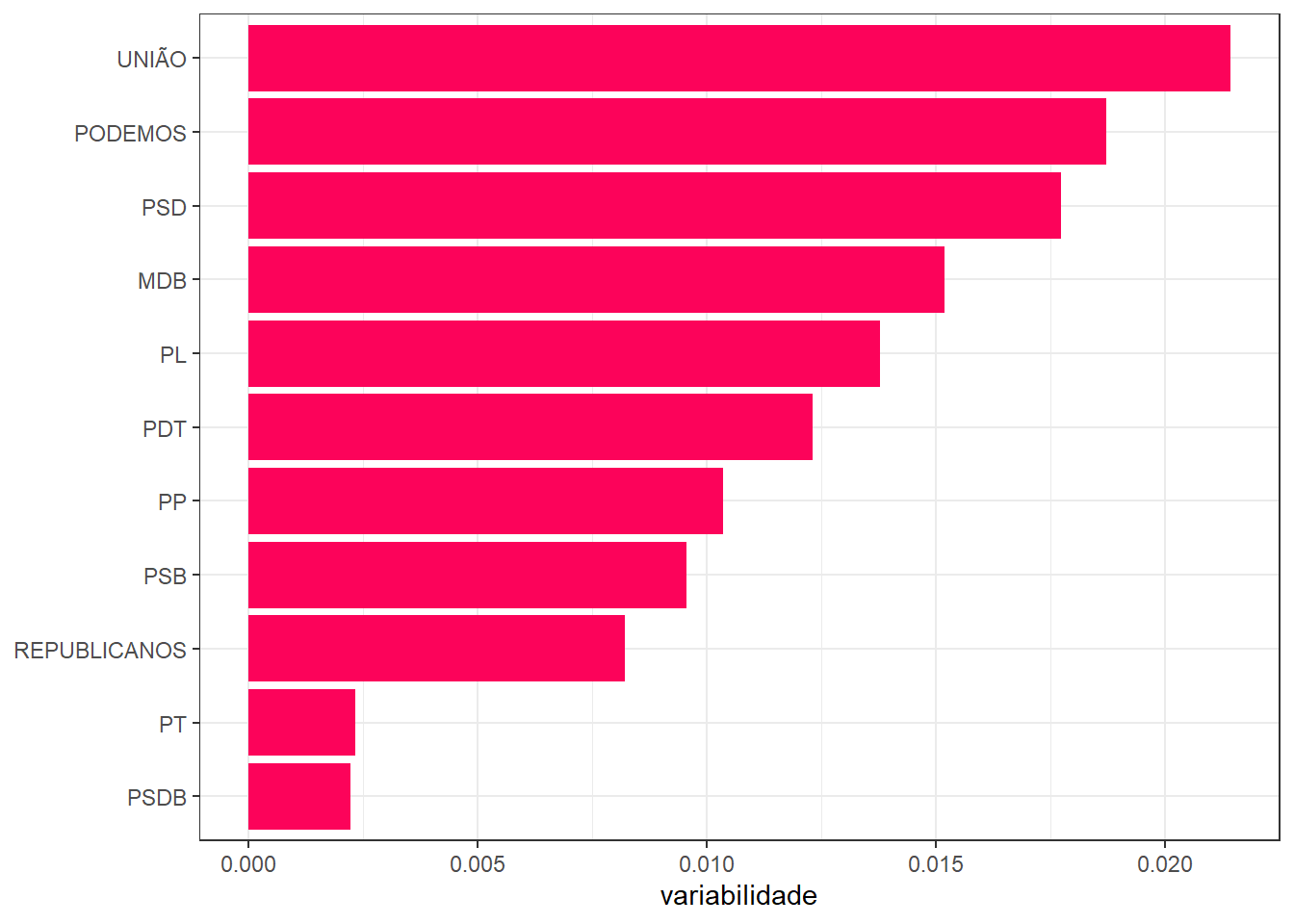
É possível observar que o partido menos coeso é o UNIÃO, seguido por PODEMOS e PSD. Já os partidos mais uniformes nas votações são o PSDB e PT. Note que REDE e NOVO foram excluídos dessa análise pois, como visto anteriormente, continham apenas um senador.
Podemos utilizar os centroides dos partidos para representar essas relações num gráfico de dispersão. No gráfico abaixo é possível observar que o PODEMOS apresenta um posicionamento afastado dos demais partidos. Já os partidos PDT, PSB e PSD aparentam uma posição muito próxima, ou seja, de forma geral, votam de maneira similar. Assim como o bloco dado por PL e NOVO (lembre que esse partido conta apenas com o senador Eduardo Girão) e, também, por PT e REDE. Note que a similaridade entre PT e REDE já era esperada, uma vez que o único senador da REDE (senador Randolfe Rodrigues) foi líder do governo do PT nesse período no senado.
# código em R
part_cent <- resultados %>%
group_by(SiglaPartido) %>%
summarise(cent1 = mean(coord1), cent2 = mean(coord2))
fig2 <- part_cent %>%
ggplot(aes(cent1, cent2, color = SiglaPartido, label = SiglaPartido)) +
geom_hline(yintercept = 0, color = "grey") +
geom_vline(xintercept = 0, color = "grey") +
geom_text() +
labs(x = NULL, y = NULL, color = NULL) +
theme_void() +
theme(legend.position = "none")
ggplotly(fig2, tooltip = "text") De forma análoga ao que fiz agrupando os senadores, é possível agrupar os partidos de acordo com as posições dos centroides. Por exemplo, podemos considerar a seguinte análise:
# código em R
dist_part <- as.matrix(dist(part_cent))
dimnames(dist_part) <- list(part_cent$SiglaPartido, part_cent$SiglaPartido)
hc <- hclust(as.dist(dist_part))
fviz_dend(
hc,
cex = 0.6,
k = 4,
main = "Agrupamento dos Partidos",
color_labels_by_k = TRUE,
k_colors = c("red", "blue" , "darkgreen", "grey40"),
horiz = TRUE
) +
theme_void()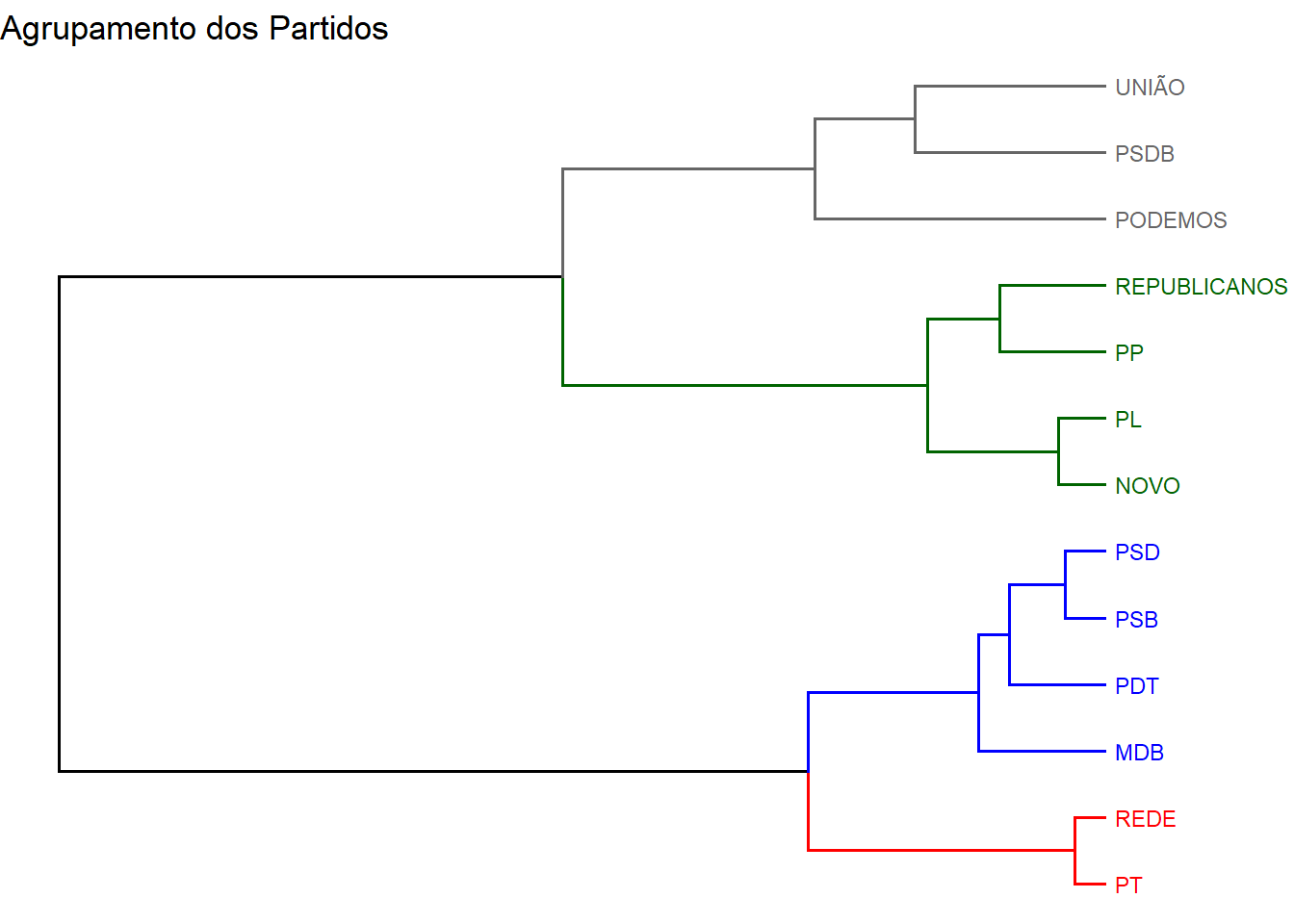
Assim, é possível observar quatro agrupamentos distintos. É interessante notar como PSD e PSB; PL e NOVO (partido contando apenas com o senador Eduardo Girão), além de PT e REDE (partido contando apenas com o senador Randolfe Rodrigues), são as duplas mais similares de partidos.
Comparação dos partidos de 2019 vs 2023
A seguir são apresentados os agrupamentos dos partidos em 2019 e 2023. Note como PT e REDE votam mais parecido em 2023. Esse comportamento também é observado entre REPUBLICANOS e PP e, também, para os partidos PSD, PSB e PDT.
O PP era mais similar ao PL em 2019. Já em 2023 esse partido é mais similar ao REPUBLICANOS.
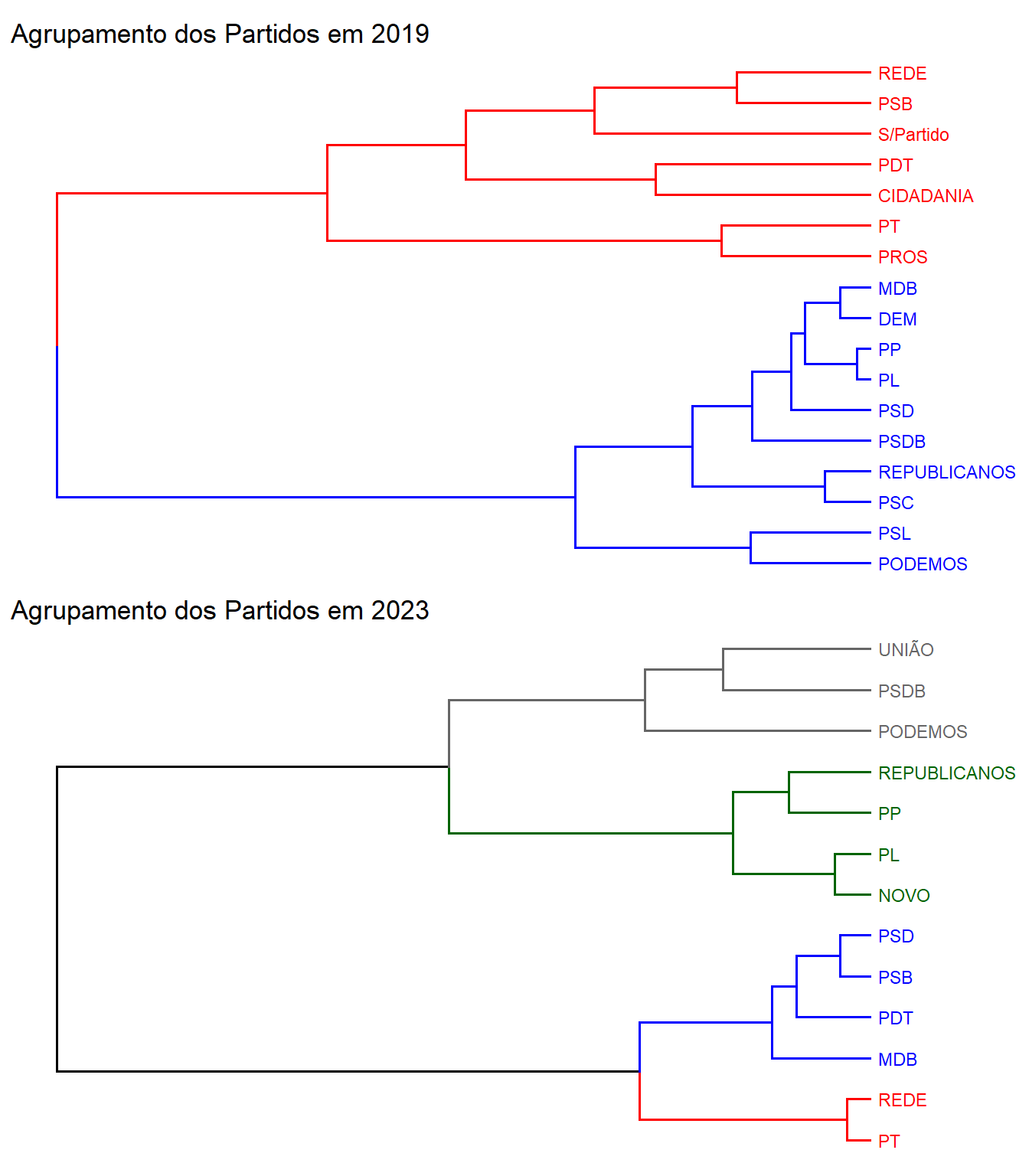
Conclusão
Nesse post atualizei a versão anterior do post (Como votaram os senadores em 2019). Novamente foi utilizado Python e R para carregar, processar, visualizar e analisar os dados.
Caso tenha alguma crítica, sugestão ou comentário, me envie uma mensagem!
Crédito da foto no início do post de Sérgio Lima.