
Um etapa fundamental no processo de avaliação do desempenho de modelos preditivos se dá a partir de métodos de reamostragem, separação dos dados em conjunto de treinamento/teste ou treinamento/teste/validação. Com base nesses métodos, tomamos a decisão de escolha ou rejeição dos modelos em avaliação. Muitas vezes esses processos passam batidos, porque já são internalizados nas bibliotecas ( ver introdução sobre tidymodels) e não se faz uma reflexão do que está acontecendo nessa etapa. Por exemplo, calcula-se um erro quadrático médio para avaliar o desempenho do modelo e não se reconhece que há uma incerteza associada a esse número.
Nesse cenário, em que trabalhamos com diversas técnicas de processamento, modelagem, avaliação e implementações, é interessante quebrar o fluxo em várias etapas e compreender cada parte para ter um melhor entendimento do fluxo completo. Essa forma de análise foi utilizada pelo famoso filósofo e matemático René Descartes (figura abaixo).
No célebre Discurso do Método Descartes enuncia o seguinte preceito (entre quatro):
“O segundo, o de dividir cada uma das dificuldades que eu examinasse em tantas partes quantas possíveis e quantas necessárias fossem para melhor resolvê-las.”
Portanto, nesse post, vamos trabalhar com um dos pequenos blocos do fluxo de modelagem para compreender melhor o processo por completo. Como o pacote rsample é utilizado no tidymodels para avaliação dos modelos e de medidas, utilizaremos esse pacote como referência. Apresentaremos a abordagem treinamento/teste, validação cruzada de Monte Carlo, validação cruzada e bootstrap.
Treinamento e Teste
Nessa abordagem utilizaremos o conjunto de dados Boston para fazer a avaliação do erro quadrático médio de um modelo linear utilizando a função initial_split. Primeiro, vamos fazer a leitura dos dados
library(tidyverse)
library(MASS)
dim(Boston)[1] 506 14Assim, verificamos que possuímos 506 observações de 14 variáveis (13 preditoras e a variável resposta medv). De forma mais detalhada
head(Boston) crim zn indus chas nox rm age dis rad tax ptratio black lstat
1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
medv
1 24.0
2 21.6
3 34.7
4 33.4
5 36.2
6 28.7Agora vamos fazer a separação/split dos dados com a função initial_split.
library(rsample)
set.seed(123)
Boston_split <- initial_split(Boston, prop = .80)
Boston_split<Training/Testing/Total>
<404/102/506>Esse objeto mostra que temos 405 observações para treinamento e 101 observações para teste de um total de 506 observações. Contidos em Boston_split, possuímos os seguintes objetos:
names(Boston_split)[1] "data" "in_id" "out_id" "id" em que
data: é o data frame que foi utilizado para o splitin_id: indica quais observações foram aleatorizadas para o conjunto de treinamentoout_id: indica quais observações foram aleatorizadas para o conjunto de testeid: indica um rótulo para esse objeto
Para acessar esses elementos, você pode utilizar o comando Boston_split$nome. Por exemplo, para acessar o data frame, utilize Boston_split$data.
Podemos selecionar diretamente o conjunto de treinamento e teste utilizando
# treinamento
dados_tr <- training(Boston_split)
# teste
dados_test <- testing(Boston_split)Assim, utilizamos dados_tr para construção do modelo e dados_test para estimar o erro de previsão da seguinte forma:
# ajuste de um modelo linear
fit_lm <- lm(medv ~ ., dados_tr)
# valores preditos com base no modelo linear
predito <- predict(fit_lm, dados_test)
# eqm
(mean((dados_test$medv - predito)^2))[1] 23.67863É importante notar que esse valor numérico depende da amostra selecionada. Se sorteássemos outra amostra de treinamento, chegaríamos em outro erro de teste. Na próxima seção repetiremos esse processo diversas vezes e avaliaremos a variabilidade dessa medida.
Monte Carlo Cross-Validation
A ideia desse método é repetir o processo de treinamento/teste diversas vezes. Ao fazer essa repetição, podemos ter uma ideia da variabilidade da medida obtida na seção anterior.
Vamos utilizar a função mc_cv. Nessa aplicação utilizaremos os seguintes argumentos:
prop: é a proporção dos dados que deverá ser separada para treinamento/ajuste do modelotimes: é o número de vezes que repetiremos esse processo
Assim, para ilustrar esse procedimento, consideraremos novamente 80% dos dados para treinamento e repetiremos o processo 25 vezes.
set.seed(123)
Boston_slipts <- mc_cv(Boston, prop = 0.8, times = 25)
Boston_slipts# Monte Carlo cross-validation (0.8/0.2) with 25 resamples
# A tibble: 25 × 2
splits id
<list> <chr>
1 <split [404/102]> Resample01
2 <split [404/102]> Resample02
3 <split [404/102]> Resample03
4 <split [404/102]> Resample04
5 <split [404/102]> Resample05
6 <split [404/102]> Resample06
7 <split [404/102]> Resample07
8 <split [404/102]> Resample08
9 <split [404/102]> Resample09
10 <split [404/102]> Resample10
# … with 15 more rowsA função mc_cv nos retorna um tibble. Esse tibble apresenta uma coluna chamada splits contendo as informações da reamostragem e outra coluna id com o rótulo de cada amostra. Primeiro, vamos inspecionar os elementos da coluna splits
Boston_slipts$splits[[1]]<Analysis/Assess/Total>
<404/102/506>Isso nos informa que o primeiro elemento da coluna splits apresenta 405 observações para treinamento, 101 para teste e um total de 506 observações. Como queremos ajustar um modelo e avaliar o erro quadrático médio para cada elemento da coluna splits, criaremos uma função para isso e a aplicaremos a cada elemento dessa coluna. A seguir vamos criar essa função:
# df será o data frame dado por cada elemento da coluna splits
eqm_lm <- function(df){
tr <- analysis(df) # conjunto de treinamento
test <- assessment(df) # conjunto de teste
fit <- lm(medv ~ ., tr)
predito <- predict(fit, test)
mean((test$medv - predito)^2)
}Assim, de forma muito simples, podemos aplicar essa função a todos os elementos do objeto Boston_splits com a função map_dlb do pacote purrr.
Boston_splits <- Boston_slipts %>%
mutate(eqm = map_dbl(splits, eqm_lm))
Boston_splits# Monte Carlo cross-validation (0.8/0.2) with 25 resamples
# A tibble: 25 × 3
splits id eqm
<list> <chr> <dbl>
1 <split [404/102]> Resample01 23.7
2 <split [404/102]> Resample02 24.0
3 <split [404/102]> Resample03 25.7
4 <split [404/102]> Resample04 22.4
5 <split [404/102]> Resample05 30.2
6 <split [404/102]> Resample06 32.1
7 <split [404/102]> Resample07 23.3
8 <split [404/102]> Resample08 20.3
9 <split [404/102]> Resample09 16.8
10 <split [404/102]> Resample10 26.1
# … with 15 more rowsPara ter uma ideia visual dessa variabilidade, podemos fazer um gráfico com o eqm calculado para cada amostra e uma reta indicando o valor médio do eqm para essas 25 amostras.
Boston_splits %>%
ggplot(aes(id, eqm)) +
geom_hline(yintercept = mean(Boston_splits$eqm), color = "red", size = 1.2) +
geom_point(size = 3, color = "steelblue") +
theme_bw() +
coord_flip()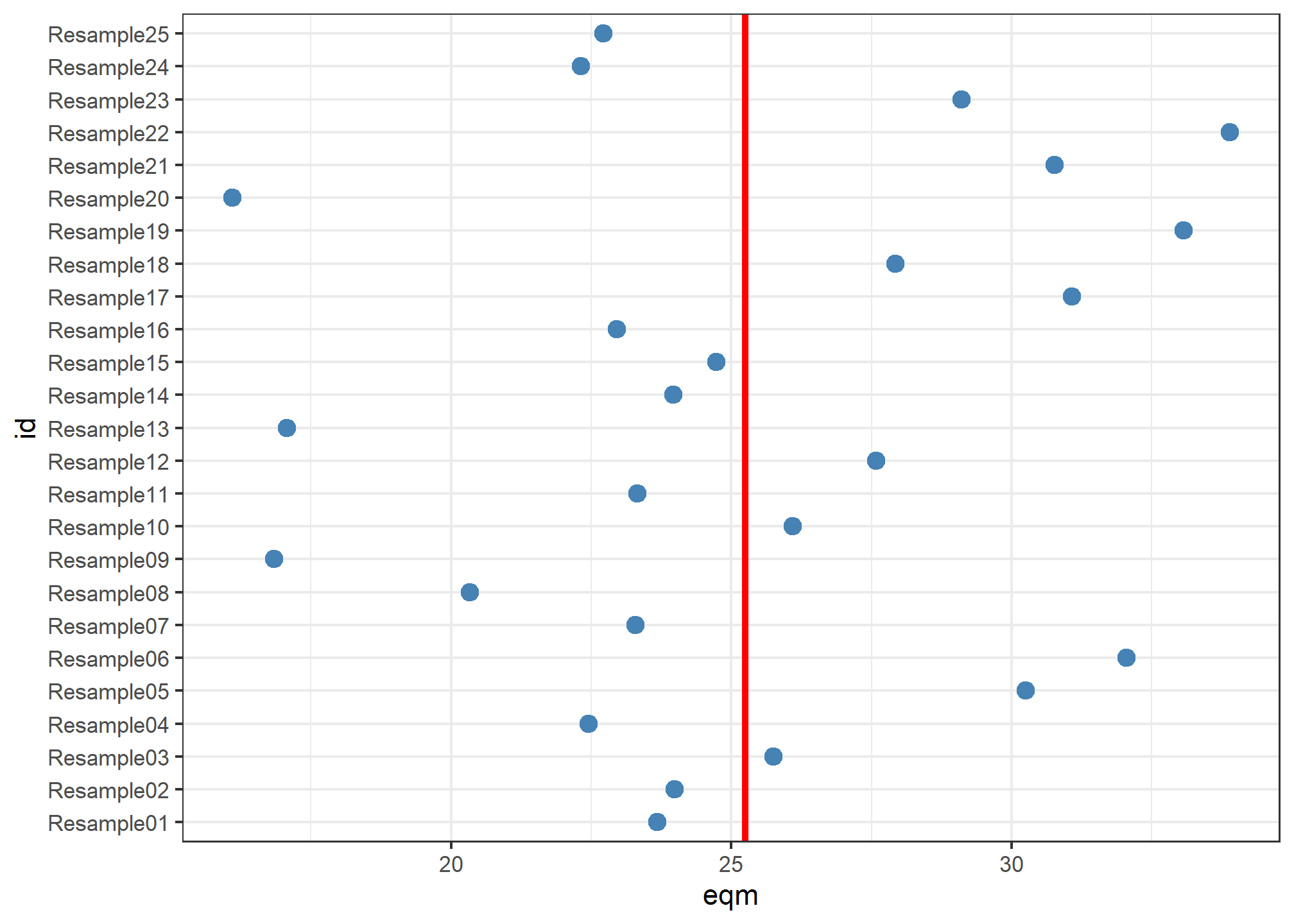
Note que, dependendo da amostra utilizada, o eqm variou de 16.1 a 33.89. Veja que, dependendo da situação, a variabilidade desses erros calculados poderiam levar a diferentes conclusões. Por exemplo, ao efetuar esse procedimento uma única vez poderíamos obter uma observação com um erro tão alto quanto ao da amostra 07 ou com um erro tão baixo quando ao da amostra 15.
Validação Cruzada
O método da validação cruzada é um dos métodos mais utilizados para avaliação dos modelos ou especificação de hiperparâmetros. Considere um cenário em que temos 12 observações e faremos a separação dessas observações em 4 folds/grupos. Portanto, teremos 3 observações por fold/grupo. Abaixo apresentamos um possível resultado para esse cenário.

Vamos aplicar esse método ao conjunto de dados visto anteriormente. Aqui utilizaremos a função vfold_cv. O argumento v indica o número de folds/grupos para a separação dos dados.
set.seed(123)
Boston_cv <- vfold_cv(Boston, v = 10)
Boston_cv# 10-fold cross-validation
# A tibble: 10 × 2
splits id
<list> <chr>
1 <split [455/51]> Fold01
2 <split [455/51]> Fold02
3 <split [455/51]> Fold03
4 <split [455/51]> Fold04
5 <split [455/51]> Fold05
6 <split [455/51]> Fold06
7 <split [456/50]> Fold07
8 <split [456/50]> Fold08
9 <split [456/50]> Fold09
10 <split [456/50]> Fold10Note que a variável id agora indica o Fold ao qual cada elemento da coluna splits corresponde. Assim, podemos utilizar novamente a função eqm_lm que criamos anteriormente para cada fold/grupo.
Boston_cv <- Boston_cv %>%
mutate(eqm = map_dbl(splits, eqm_lm))
Boston_cv# 10-fold cross-validation
# A tibble: 10 × 3
splits id eqm
<list> <chr> <dbl>
1 <split [455/51]> Fold01 11.7
2 <split [455/51]> Fold02 11.7
3 <split [455/51]> Fold03 43.7
4 <split [455/51]> Fold04 12.3
5 <split [455/51]> Fold05 23.1
6 <split [455/51]> Fold06 20.9
7 <split [456/50]> Fold07 40.9
8 <split [456/50]> Fold08 14.1
9 <split [456/50]> Fold09 42.7
10 <split [456/50]> Fold10 22.7Dessa forma, a estimativa do erro de previsão com base na validação cruzada em 10 lotes será dada por:
mean(Boston_cv$eqm)[1] 24.37722Podemos combinar a validação cruzada com o que vimos na seção anterior (Monte Carlo Cross-Validation). Para isso, utilizaremos o argumento repeats. Por exemplo, vamos repetir o procedimento de validação cruzada 25 vezes.
set.seed(123)
Boston_cv <- vfold_cv(Boston, v = 10, repeats = 25)
Boston_cv# 10-fold cross-validation repeated 25 times
# A tibble: 250 × 3
splits id id2
<list> <chr> <chr>
1 <split [455/51]> Repeat01 Fold01
2 <split [455/51]> Repeat01 Fold02
3 <split [455/51]> Repeat01 Fold03
4 <split [455/51]> Repeat01 Fold04
5 <split [455/51]> Repeat01 Fold05
6 <split [455/51]> Repeat01 Fold06
7 <split [456/50]> Repeat01 Fold07
8 <split [456/50]> Repeat01 Fold08
9 <split [456/50]> Repeat01 Fold09
10 <split [456/50]> Repeat01 Fold10
# … with 240 more rowsObserve que agora a coluna id corresponde a repetição a qual pertence cada um dos folds/grupos indicados na coluna id2. Como temos v = 10 e repeats = 25, de fato, devemos ter 250 elementos nesse tibble.
Vamos calcular o eqm para cada combinação com auxílio da função eqm_lm (definida anteriormente).
Boston_cv <- Boston_cv %>%
mutate(eqm = map_dbl(splits, eqm_lm))
Boston_cv# 10-fold cross-validation repeated 25 times
# A tibble: 250 × 4
splits id id2 eqm
<list> <chr> <chr> <dbl>
1 <split [455/51]> Repeat01 Fold01 11.7
2 <split [455/51]> Repeat01 Fold02 11.7
3 <split [455/51]> Repeat01 Fold03 43.7
4 <split [455/51]> Repeat01 Fold04 12.3
5 <split [455/51]> Repeat01 Fold05 23.1
6 <split [455/51]> Repeat01 Fold06 20.9
7 <split [456/50]> Repeat01 Fold07 40.9
8 <split [456/50]> Repeat01 Fold08 14.1
9 <split [456/50]> Repeat01 Fold09 42.7
10 <split [456/50]> Repeat01 Fold10 22.7
# … with 240 more rowsAgora, podemos apresentar um gráfico com os valores individuais e médios do eqm para cada repetição.
ggplot(Boston_cv) +
geom_point(aes(id, eqm), color = "steelblue", size = 2, alpha = .5) +
stat_summary(aes(id, eqm), fun = mean, geom = "point", color = "red", size = 3) +
theme_bw() +
coord_flip()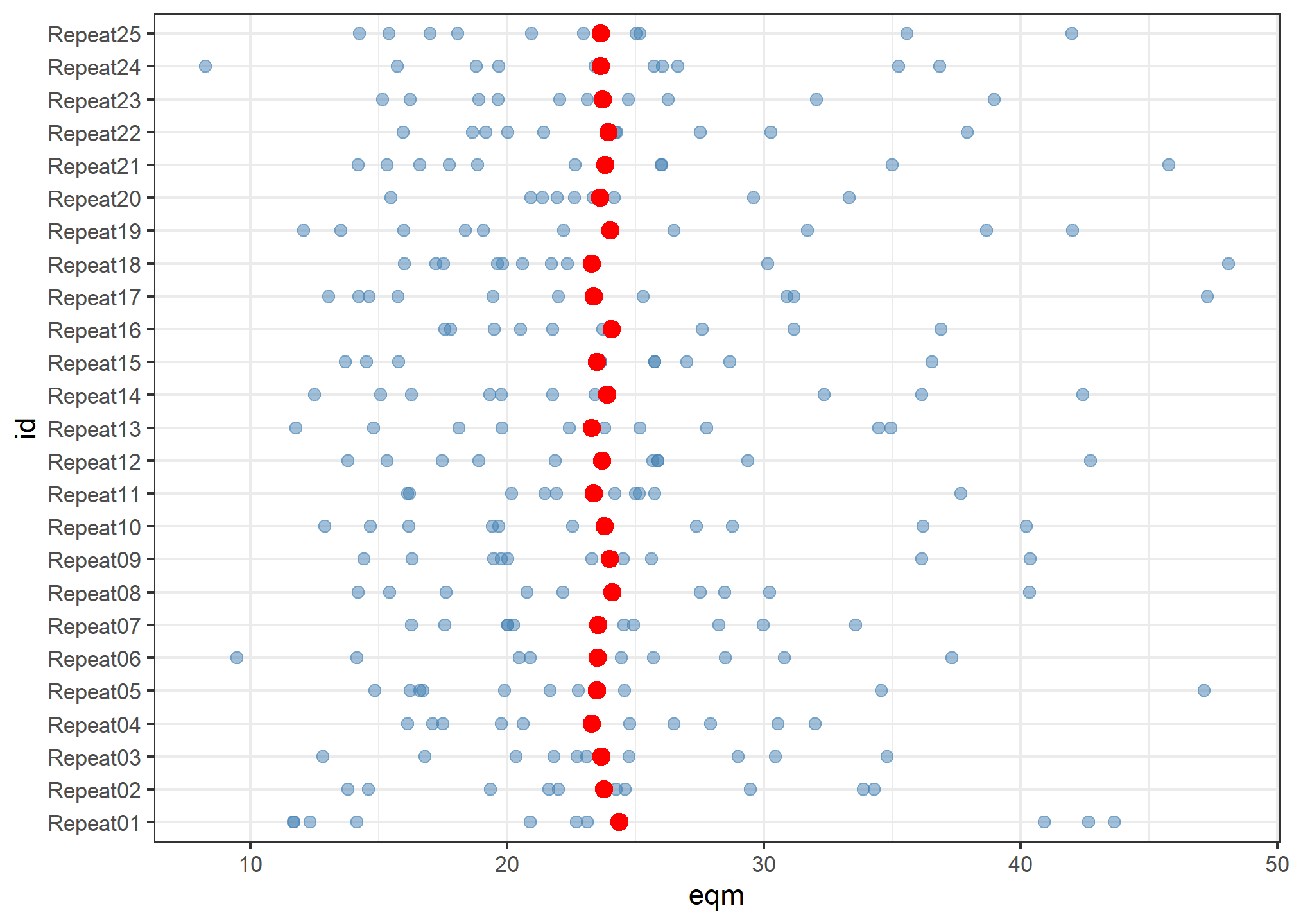
Aqui é importante notar que, embora exista uma grande variação dos valores do eqm para cada amostra de validação cruzada, a média do eqm para cada repetição (pontos vermelhos) é muito próxima para as diferentes amostragens.
Bootstrap
Utilizaremos outro exemplo para ilustrar uma aplicação de bootstrap. Esse exemplo foi retirado do livro An Introduction to Statistical Learning with Applications in R. Nessa ilustração, temos dois ativos financeiros com retornos dados por \(X\) e \(Y\). A seguir apresentamos essas observações.
library(ISLR)
library(rsample)
Portfolio %>%
ggplot(aes(X, Y)) +
geom_point(size = 3, color = "steelblue", alpha = .5) +
theme_bw()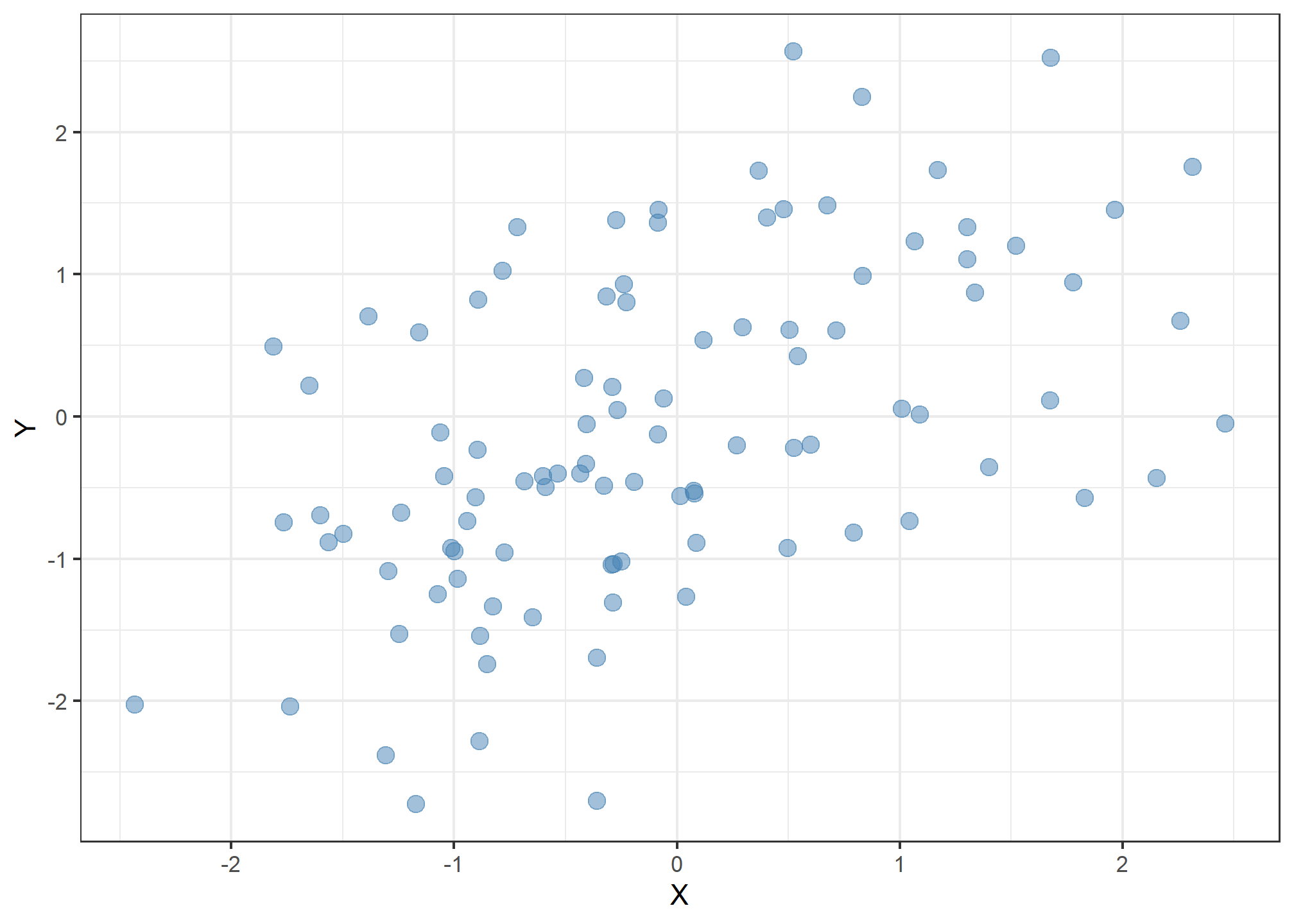
O objetivo é investir uma proporção \(\alpha\) em \(X\) e o restante \((1 - \alpha)\) em \(Y\) tomando \(\alpha\) como o valor que minimiza o risco (dado pela variância) desse investimento. Note que o risco é dado por
\[\text{Var}\big[\alpha X + (1 - \alpha)Y\big].\]
Assim, para encontrar o valor de \(\alpha\) que minimiza essa variância, vamos desenvolver a equação anterior denotando esse risco por \(r(\alpha)\).
\[ \begin{aligned} r(\alpha) & = \text{Var}\big[\alpha X + (1 - \alpha)Y\big] \\ &= \text{Var}\big[\alpha X\big] + \text{Var}\big[(1 - \alpha)Y\big] + 2\text{Cov}\big[\alpha X, (1 - \alpha)Y \big] \\ &= \alpha^2\text{Var}\big[ X\big] + (1 - \alpha)^2\text{Var}\big[Y\big] + 2\alpha(1 - \alpha)\text{Cov}\big[ X, Y \big] \\ &= \alpha^2\sigma^2_X + (1 - \alpha)^2\sigma^2_Y + 2\alpha(1 - \alpha)\sigma_{XY}. \\ \end{aligned} \]
Portanto, para minimizar esse risco, fazemos:
\[ \begin{aligned} \frac{\partial r(\alpha)}{\partial \alpha} & = 0.\\ \end{aligned} \]
Dessa forma,
\[ \begin{aligned} 2\alpha\sigma^2_X - 2(1 - \alpha)\sigma^2_Y + 2\sigma_{XY} - 4\alpha\sigma_{XY} = 0.\\ \end{aligned} \]
Logo,
\[\alpha = \frac{\sigma^2_Y - \sigma_{XY}}{\sigma^2_X + \sigma^2_Y - 2\sigma_{XY}}.\]
Note que não conseguimos definir o valor de \(\alpha\) porque não conhecemos as variâncias de \(X\) e \(Y\), assim como a covariância entre essas medidas. Uma alternativa seria substituir os parâmetros por suas respectivas estimativas. Com isso, podemos obter uma estimativa para \(\alpha\) da seguinte forma
(alpha <- (var(Portfolio$Y) - cov(Portfolio$X, Portfolio$Y))/(var(Portfolio$X) + var(Portfolio$Y) - 2*cov(Portfolio$X, Portfolio$Y)))[1] 0.5758321É importante notar que não temos nenhuma ideia da variabilidade dessa medida. Uma forma fácil de se obter uma medida para isso (e.g. erro padrão) se dá com a utilização de amostras bootstrap (nesse caso, amostras com reposição com o mesmo tamanho da amostra original). A seguir vamos ver como utilizar a função bootstrap do pacote rsample. Inicialmente vamos utilizar essa função para criar 5.000 amostras bootstrap (argumento times).
amostras_boot <- bootstraps(Portfolio, times = 5000)
amostras_boot# Bootstrap sampling
# A tibble: 5,000 × 2
splits id
<list> <chr>
1 <split [100/38]> Bootstrap0001
2 <split [100/37]> Bootstrap0002
3 <split [100/40]> Bootstrap0003
4 <split [100/40]> Bootstrap0004
5 <split [100/41]> Bootstrap0005
6 <split [100/35]> Bootstrap0006
7 <split [100/40]> Bootstrap0007
8 <split [100/42]> Bootstrap0008
9 <split [100/41]> Bootstrap0009
10 <split [100/35]> Bootstrap0010
# … with 4,990 more rowsO comando bootstraps cria um tibble com a primeira coluna indicando os splits e a segunda coluna indicando o id de cada amostra bootstrap. Vamos verificar como é definido cada elemento da primeira coluna.
amostras_boot$splits[[1]]<Analysis/Assess/Total>
<100/38/100>Assim, temos uma amostra de 100 observações (mesmo tamanho da original) e 38 observações out-of-bag (ou seja, que não entraram nessa amostra). Além disso, esse objeto possui alguns elementos
names(amostras_boot$splits[[1]])[1] "data" "in_id" "out_id" "id" O objeto data apresenta os dados originais utilizados para o processo de reamostragem, o objeto in_id apresenta quais observações entraram na amostra bootstrap, o objeto out_id indica quais observações ficaram fora da amostra bootstrap e o objeto id indica o rótulo dessa amostra bootstrap.
Para acessar a amostra bootstrap e a amostra out-of-bag, podemos utilizar os comandos
# amostra bootstrap
analysis(amostras_boot$splits[[1]]) %>%
head() X Y
61 -0.4036473 -0.05438992
61.1 -0.4036473 -0.05438992
6 -1.7371238 -2.03719104
84 -0.6004857 -0.42094053
27 1.0909180 0.01449451
16 0.0425493 -1.26757362# amostra out-of-bag
assessment(amostras_boot$splits[[1]]) %>%
head() X Y
1 -0.8952509 -0.2349235
2 -1.5624543 -0.8851760
3 -0.4170899 0.2718880
4 1.0443557 -0.7341975
8 2.1528679 -0.4341386
15 0.2940159 0.6285895Agora que temos todos os ingredientes necessários para estimar o erro padrão de \(\alpha\), podemos voltar às amostras bootstrap. Lembre que trabalharemos direto com cada elemento da coluna splits do seguinte tibble
amostras_boot# Bootstrap sampling
# A tibble: 5,000 × 2
splits id
<list> <chr>
1 <split [100/38]> Bootstrap0001
2 <split [100/37]> Bootstrap0002
3 <split [100/40]> Bootstrap0003
4 <split [100/40]> Bootstrap0004
5 <split [100/41]> Bootstrap0005
6 <split [100/35]> Bootstrap0006
7 <split [100/40]> Bootstrap0007
8 <split [100/42]> Bootstrap0008
9 <split [100/41]> Bootstrap0009
10 <split [100/35]> Bootstrap0010
# … with 4,990 more rowsAssim, para cada elemento da coluna splits, iremos aplicar uma função para calcular o valor de \(\alpha\) estimado para a respectiva amostra. Primeiro, vamos criar a função alpha para automatizar esse cálculo.
alpha <- function(df){
aux <- analysis(df)
(var(aux$Y) - cov(aux$X, aux$Y)) /
(var(aux$X) + var(aux$Y) - 2*cov(aux$X, aux$Y))
}Assim, de forma muito simples, podemos aplicar essa função a todos os elementos do objeto amostras_boot com a função map_dbl do pacote purr.
amostras_boot <- amostras_boot %>%
mutate(alpha = map_dbl(splits, alpha))
head(amostras_boot)# A tibble: 6 × 3
splits id alpha
<list> <chr> <dbl>
1 <split [100/38]> Bootstrap0001 0.788
2 <split [100/37]> Bootstrap0002 0.665
3 <split [100/40]> Bootstrap0003 0.498
4 <split [100/40]> Bootstrap0004 0.594
5 <split [100/41]> Bootstrap0005 0.615
6 <split [100/35]> Bootstrap0006 0.559Uma vez que temos os valores estimados de \(\alpha\) para cada amostra, para obter uma estimativa do erro padrão de \(\alpha\), basta utilizar a seguinte expressâo:
\[\text{SE}_{B}(\hat{\alpha}) = \sqrt{\frac{1}{B-1}\sum_{r = 1}^{B}\bigg(\hat{\alpha}^{*r} - \overline{\hat{\alpha}^{*r}}\bigg)^2}.\]
Assim,
amostras_boot %>%
summarise(se = sd(alpha))# A tibble: 1 × 1
se
<dbl>
1 0.0897Portanto, a estimativa do erro padrão para essa medida é dada por 0.0897299. Além dessa medida de variabilidade, podemos utilizar os valores de \(\alpha\) com as amostras bootstrap para gerar um intervalo de confiança com base nos percentis da distribuição observada. A seguir apresentamos a distribuição desse valores.
amostras_boot %>%
ggplot(aes(alpha)) +
geom_histogram(aes(y = ..density..),
fill = "steelblue", color = "black") +
theme_bw()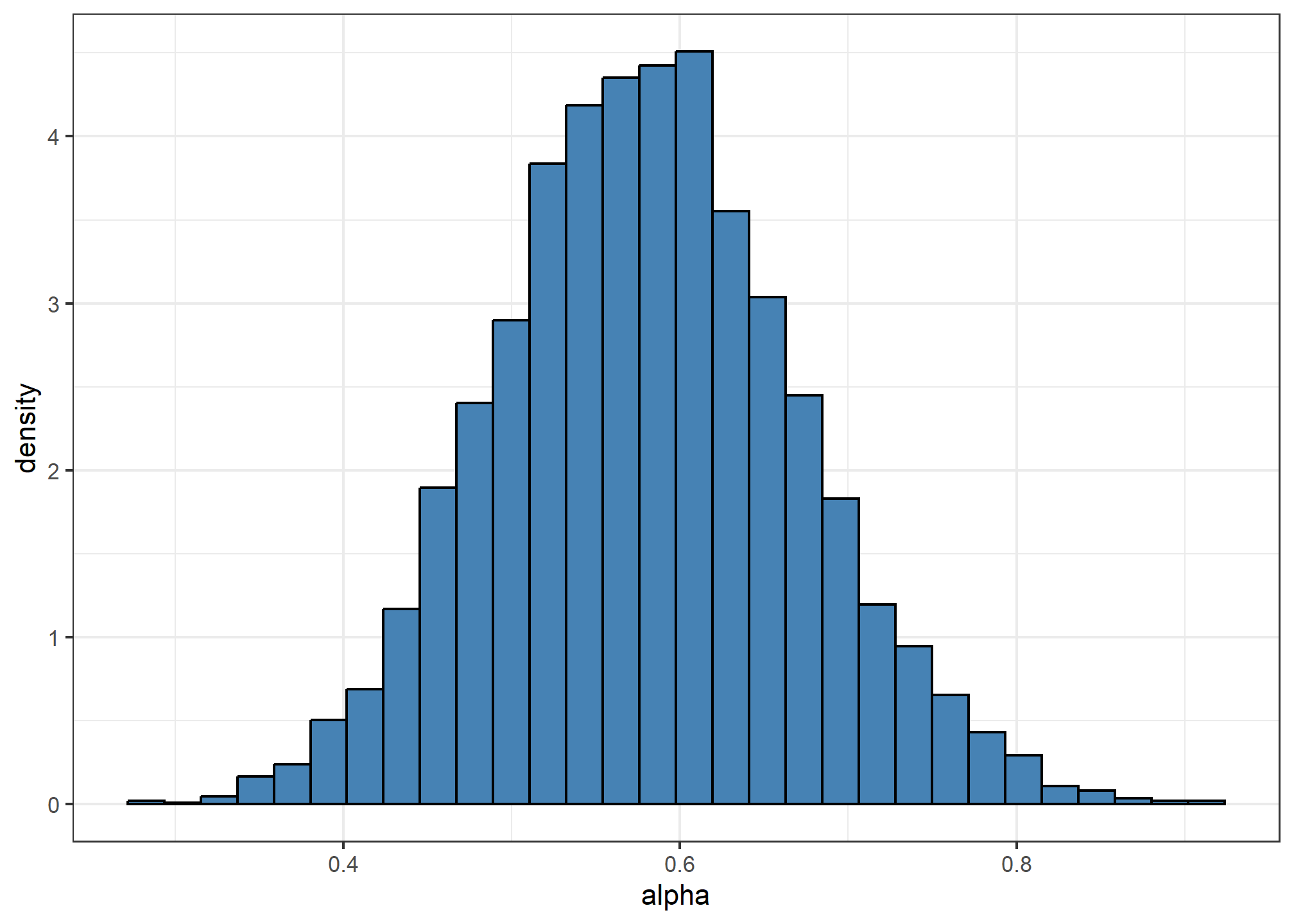
Por exemplo, para um intervalo de confiança de 95%, utilizaremos
\[\big[ \alpha^*_{2.5\%} ; \alpha^*_{97.5\%}\big],\]
em que \(\alpha^*_{k\%}\) corresponde ao \(k\)-percentil dos valores de \(\alpha\) obtidos com as amostras bootstrap. Assim, esse intervalo é dado por
amostras_boot %>%
summarise(LI = quantile(alpha, probs = 0.025),
LS = quantile(alpha, probs = 0.975))# A tibble: 1 × 2
LI LS
<dbl> <dbl>
1 0.409 0.765Conclusão
Agora compreendemos melhor uma pequena parte do fluxo de modelagem que é dado pela utilização de métodos de reamostragem e divisão de dados. Essa parte é vital para o processo de modelagem e é utilizada de forma muito prática no padrão utilizado no tidymodels. Além disso, podemos utilizar essas abordagens para realizar simulações computacionais de forma muito simplificada.
Caso tenha alguma crítica, sugestão ou comentário, me envie uma mensagem!